transcription-compare
Python tools to compare output transcript to reference
Project maintained by voicegain Hosted on GitHub Pages — Theme by mattgraham
Utility to compare output transcript to reference
Uses Ukkonen algorithm to efficiently compute Leveshtein distance and character error rate (CER).
Additionally it can output alignment information.
Usage
Usage: transcribe-compare [OPTIONS]
Transcription compare tool provided by VoiceGain
Options:
-r, --reference TEXT source string
-o, --output TEXT target string
-R, --reference_file FILENAME source file path
-O, --output_file FILENAME target file path
-a, --alignment Do you want to see the alignment result?
True/False
-e, --error_type [CER|WER]
-j, --output_format [JSON|TABLE]
-l, --to_lower Do you want to lower all the words?
True/False
-p, --remove_punctuation Do you want to remove all the punctuation?
True/False
-P, --to_save_plot Do you want to see the windows? True/False
-s, --to_edit_step INTEGER Please enter the step
-w, --to_edit_width INTEGER Please enter the width
--help Show this message and exit.
Dependencies
- click
- inflect
- re
- nltk
- metaphone
- matplotlib
Sample Commands
python transcribe-compare -R sample_data/The_Princess_and_the_Pea-reference.txt -O sample_data/The_Princess_and_the_Pea-output-1.txt -e CER
HTML Output
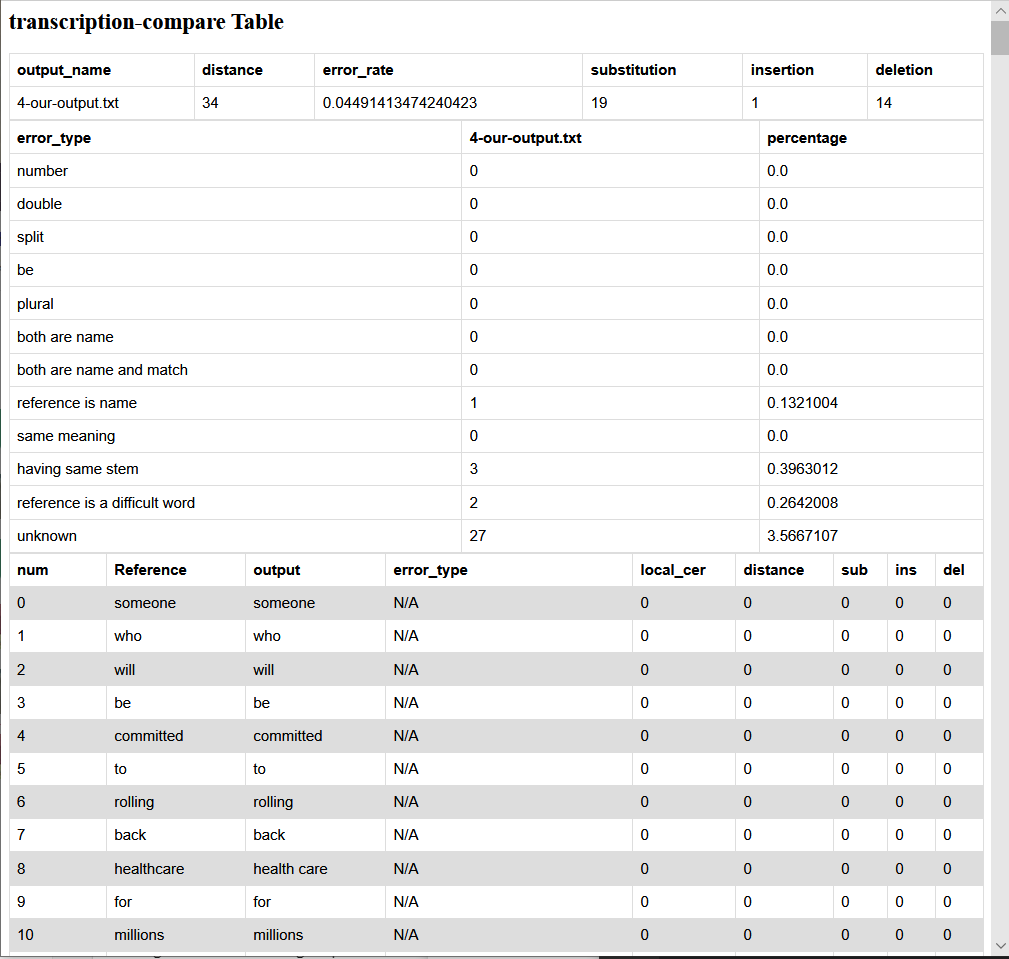
Related code
There is a script available that using transcribe-compare to compare results from Voicegaing and Google recognizers. You can find it here: https://github.com/voicegain/platform/tree/master/utility-scripts/test-transcribe
Acknowledgements
Contributed by VoiceGain.
VoiceGain provides Deep-Neural-Network-based Speech-to-Text (ASR) available in Cloud and also as an Edge Deployment. Accessible via RESTful Web API or MRCP v2 interface. Is suitable both for continuous large-vocabulary transcription (real-time or off-line) and for recognition using context-free grammars (e.g. GRXML). In addition to this VoiceGain platform provides API-driven method to modify models used in speech-to-text. It is possible to modify language model, pronunciation model, and the acoustic DNN model.